DataPipeline using Apache Beam and Google Cloud DataFlow as Runner and BigQuery as DataSink

In this article, we will be looking into creating a data pipeline using Google Cloud Platform(GCP) services. I have been learning through Coursera specialization in Data Engineering, Big Data, and Machine Learning GCP thought of creating something outside of the course on my own. Luckily I got a nice use case where I was working recently on AWS s3 log analysis. And I have done all this using my free account in the GCP console. Also, there is a walkthrough video added at the end, performing all the actions on GCP!!!
Use Case Goes like this:
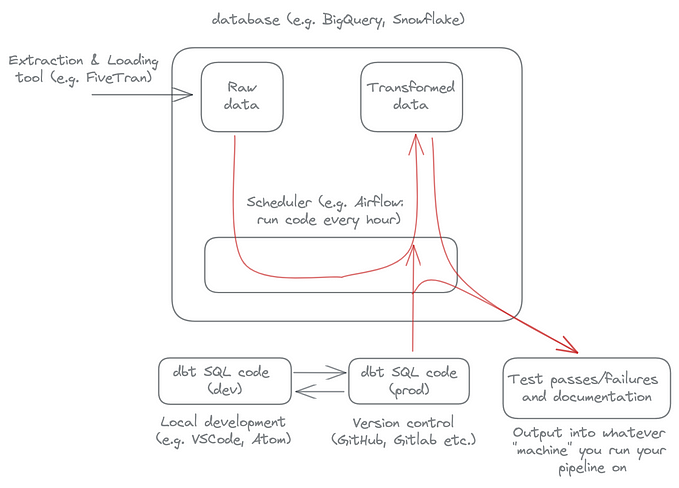
Download Logs →Upload Logs to Google Storage → Trigger DataFlow
Responsibility of a DataFlow Job:
Read Logs Files → Parse Log Files →Write To BigQuery
For what?
BigQuery is used to generate reports required from the S3 logs.
I will provide all the links that I have gone through while creating this pipeline. To understand each concept of this can go through these links: DataFlow, Apache Beam Python, and BigQuery.
Steps involved in creating a complete Pipeline:
- Create a Google Cloud Storage in the Region which you prefer.
- Create a BigQuery Dataset in the same project
- Create a Service Account and provide owner role
- Create Pipeline using Apache Beam
- Analyze logs using BigQuery and DataStudio
Google Cloud Storage:
Create a Bucket in the selected project in any region that is required and keep a note of the region is selected.
Create a BigQuery Dataset:
In BigQuery UI create a Dataset under the same project.
Create a Service Account:
Create a Service Account to communicate from local machine to GCP service.
Create Pipeline using Apache Beam:
This is a little time-consuming in the beginning maybe. Here we need to create a pipeline using ApacheBeam open-source library using either in Java or Python language. Here is my pipeline for the use case described above in Python.
obj = AwsLogParser()
quotes = (
p
| 'Read' >> ReadFromText(known_args.input)
| 'Parse Log' >> beam.Map(lambda line: obj.parse(line))
)quotes | beam.io.gcp.bigquery.WriteToBigQuery(
obj.table_spec,
obj.schema,
write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND,
create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED
)
This Pipeline contains three steps, Read each line from the logs and then pass it on to the Parse step. Here in the parse basically parse the s3 log lines and create a dictionary matching the column name of the BigQuery table schema. And in the final step is about populating the parsed data into a BigQuery table. One thing to note here: When we are running any pipeline in a local machine specify all the data as input to be a local path and output path also to be on local. Likewise when running the pipeline using DataFlow runner needs to specify Google Storage files paths. I made the mistake of runner the pipeline on the cloud by specifying the local path for input. The problem here is, the pipeline will execute successfully but the table won't get created in the BigQuery since there is no data.
And the command to run above:
export GOOGLE_APPLICATION_CREDENTIALS="/path/to/your/json_file.json"export PROJECT=your_project_id
export BUCKET=your_bucket_id
export REGION=your_regionpython main.py \
--region $REGION \
--runner DataflowRunner \
--project $PROJECT \
--temp_location gs://$BUCKET/tmp/ \
--input gs://$BUCKET/aws_logs/2020*
Once this is running we can see the status on the Web UI as well in the GCP. It does take time, need to be a bit patient.
Analyzing the Logs using BigQuery and DataStudio:
BigQuery is the Datawarehoue maintained by Google. It provides a simple rich MySql type syntax approach to get the analytics on petabytes of data.
Here in our case we are parsing the s3 log and storing all the info in the table. Here to keep it simple, we will query only 200 requests and the key to be ending with HTML.
SELECT
key,
request_uri,
http_status,
date
FROM
`justlikethat-294122.s3_logs.access_report`
WHERE
http_status='200' and ends_with(key, 'html')
LIMIT
1000We then will realize the result from the above query with a pie chart using Google DataStudio.

Likewise, any type of chart can be obtained.
What Next?
Once the report is created either using a template provided by Google Datastudio or created on your own, it can easily be integrated into your website by embedding the report to the respective website using iframe. That is not covered here.
Links:
https://medium.com/swlh/apache-beam-google-cloud-dataflow-and-creating-custom-templates-using-python-c666c151b4bchttps://github.com/ankitakundra/GoogleCloudDataflow/blob/master/dataingestion.pyhttps://stackoverflow.com/questions/55694541/error-unable-to-parse-file-when-i-run-a-custom-template-on-dataflowhttps://cloud.google.com/dataflow/docs/quickstarts/quickstart-pythonhttps://github.com/apache/beam/blob/master/sdks/python/apache_beam/examples/wordcount.pyhttps://beam.apache.org/documentation/io/built-in/google-bigquery/
Walkthrough:
EndNote:
It was a good experience doing this complete flow. Felt like I achieved something cool. I do have experience dealing with multiple servers on-premise, but this is a different experience doing it all in the cloud, Code is available here. This is it!!! Thanks for reading cheers!!! enjoy coding!!!